If you were young in the 00s, you may have run into the arcade light-gun game “House of the Dead” which is a rail shooter where you have to fight through zombies to survive.
I recently discovered that there is a version of this game called “Typing of the Dead” where you have to type words to kill zombies instead of shooting them.
This was sold as a tool to help people learn how to type, but I am more interested in using it for learning languages.
Therefore the question arose:
Can we hack the game to include custom vocabulary for language learning?
Use WinCdEmu to mount theTyping of the Dead, The (Japan).cue file
Go to the mounted drive and run Setup.exe
Display Japanese chars in Setup
You may have issues reading the setup:
Go to Settings > Time & Language > Language & Region
Click Administrative language settings
Click Change system locale
Check Beta: Use Unicode UTF-8 for worldwide language support
Restart your computer
Find serial
In order to install we need a serial number. I first tried the one from the Abandonware site, which is marked for the English version, but it didn’t work. After some searching I found the correct format in this thread: oshiete.goo.ne.jp/qa/252031.html.
TLDR the structure follows the pattern TODXXXXX-XXXXXX-XXXXX, where X is a digit. You can take the serial from the Abandonware site and replace the prefix.
Running the game
Use Locale Emulator to run the game in a Japanese locale: LocaleEmulator
Set compatibility mode to Windows XP
At this point we are ready to play:
Out of box, the game can be used to practice Japanese, but the lack of vocab-customization means it’s not ideal for language learning.
Hacking the dictionary
The vocabulary used in the game is stored in the /word folder as .bin files.
In order to modify, we need to understand the file format.
The main structure is explained in this arcade thread by user sammargh.
In order to build the first version of the decoder, I gave Copilot the S000L010.bin file and the posts in the thread above, which, after some back and forth, resulted in correct extraction of the current vocabulary.
It then took some trial and error to figure out how to map back new vocabulary to the game, and initial attempts looked like this:
Adapt for Chinese
The game is designed for Japanese, so the engine works off Shift-JIS encoding, which means we cannot display simplified Chinese characters.
However, as a workaround, we can fallback to traditional Chinese characters.
So the phrase is the traditional version of my vocab word, and the key is the pinyin.2 version, which means 标准 -> biao1zhun3. This ensures we can easily type the keys.
Anki integration
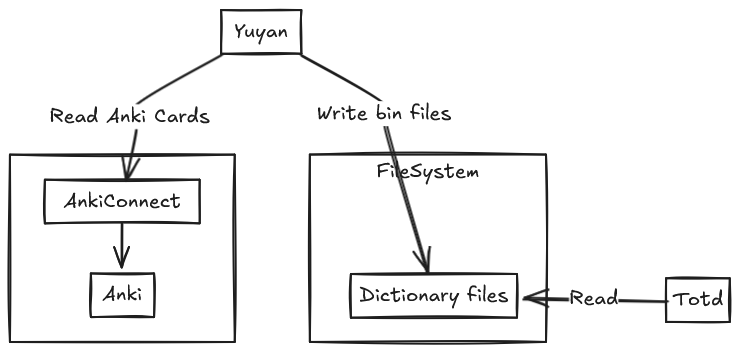
Now naturally the next step is to integrate this with Anki, so we can use the game to practice our actual vocabulary in real time, instead of static vocab.
I already have a project where I integrate Anki with some gen AI to backfill cards which lack sample sentence, audio, or image.
To connect to Anki, I use AnkiConnect which in the current software climate feels like an Anki MCP server.
It essentially hosts a local HTTP server which exposes APIs to interact with Anki, allowing us to programmatically query, create, and modify cards.
So I just dropped my code into the project and wrote a command to find cards due today with traditional and pinyin fields populated, and then generate the .bin file from it.
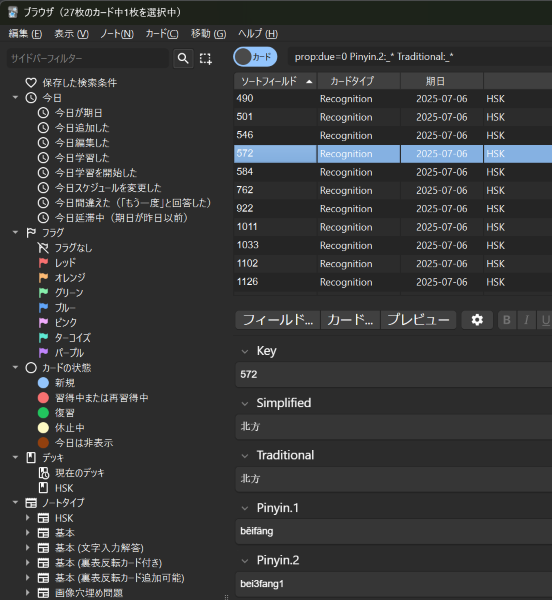
Here you can see my Anki browser where the data is taken from:
For this experiment, I tried to rely on LLMs to speed up work. As a result ~90% of the code is written by Copilot.
The file format decoding was the hardest part, and I found that I needed a larger model like Claude Opus 4 to make sense of it.
I had to go back to Ask mode for most of the work as Agent mode does not support Claude Opus 4 and the other models produced mostly garbage.
Always optimize the context for the task at hand. In this case I needed to minimize the context to the utmost essential to prevent it from getting side-tracked.
Yunnan is colorful, vibrant, and very different from what most people imagine when they think of China.
I was surprised by how little information is accessible about this region, especially when it comes to onsen.
The Tengchong area has a ton of interesting hot springs in different styles: traditional, spa-style, decorative, and open-pool-style.
I recommend Heshun as a base, situated between many hot springs. Many houses, including the one I stayed in, have onsen water in their bath.
The area is full of mountains, lakes, rivers, making for amazing views. This one is taken close to Simolawa village:
Angsana
One of the spa hotels in the area with a large selection of outdoor pools. They have a wide temperature selection, making it a good choice for beginners. Unfortunately, only a few pools are around 41-42 degrees.
Here is the water quality report from the hotel. This is bicarbonate water.
Another similar onsen hotel we visited is “the Lotus” or Hehua (荷花温泉). Hardly any presence in English, but this is it: Lotus onsen
HuangguaJing
Huangguajing has the hottest water (>43) and overall the most authentic experience without the “spa” atmosphere.
It’s small and very crowded, which can impact the experience a bit.
Rehai
Rehai has a bit of Beppu with the many decorative pools. It’s a nice, scenic path from the shuttle to the onsen.
Local Onsen
This onsen has no presence online, as far as I can tell. It’s near the road, easy to miss if you don’t know where to look.
It features several foot onsen, as well as large pools.
I like the variety that onsen pools offer, as it’s super comfortable take a swim in them.
The sunset here was amazing.
This is definitely more of a local spot, so I am happy I got to experience it.
Outside Tengchong
I also visited some onsen outside Tengchong, like Reguo (热国) near Dali. If you’re in the area, it’s worth checking out.
Food
Lastly, Yunnan’s got it all. Amazing food, fruit, coffee, and tea (the local tea is called Dianhong 滇红). The cuisine has strong influences from neighboring Thailand and Myanmar, often incorporating fruit. I am especially fond of anything with passion fruit. I had both a hotpot with passion fruit in the soup, and amazing local tomatoes with passion fruit dressing.
There are some fruits here that I have never tried before, and unfortunately don’t know the name right now.
We checked out one of the coffee plantations. I really enjoyed the local coffee and the surrounding culture. It reminds me a bit of Italy.
I recently was looking at converting CSV content to JSON in a Power Automate Flow in order to be able to work with it.
Existing articles on this topic seem to all be using inefficient loops so I decided to provide an example of an efficient Data Operations implementation.
The overall flow looks like this:
High level overview:
HTTP call gets the CSV file content
Compose to split the lines into an array
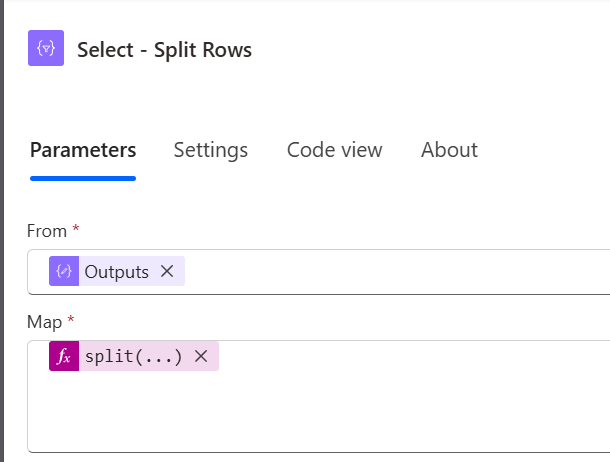
Select to split the rows into an array
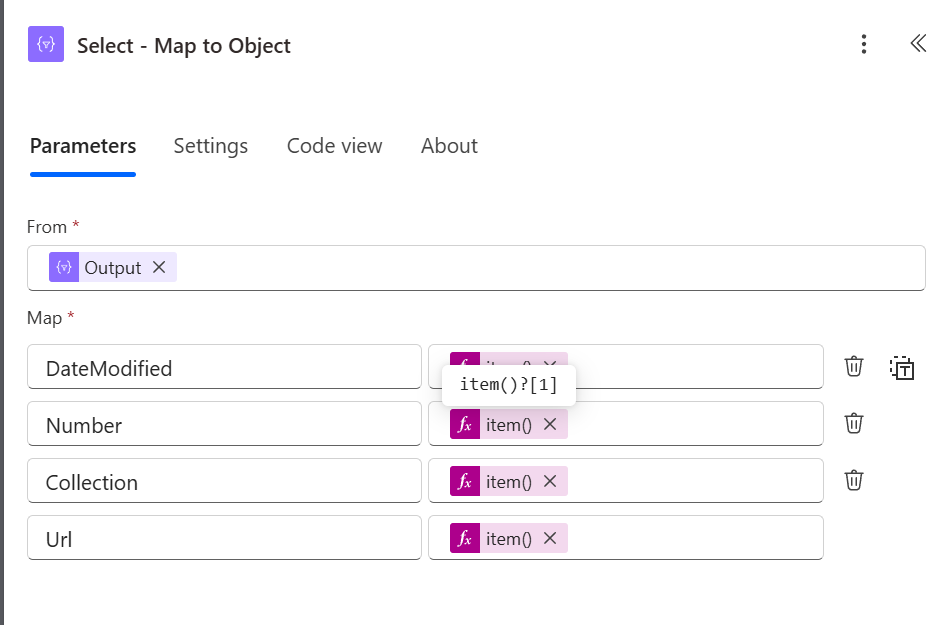
Select to map the rows to objects
Filter as an example on how to further process the objects
Split Lines
Type: Compose
Takes a single CSV string and splits it by new-line into an array of strings
It’s been some time since my initial impression post on LLMs, and since I’ve recently had an opportunity to gather my thoughts, I wanted to also summarize them here so that I can come back and see how they changed over time.
The following are rough notes of lessons learned from working with LLMs and the Agent concept.
Less is more
Usually to improve quality, we take away, rather than adding more
This means distill your prompts and systems as much as possible
As you distill your ideas, they naturally improve, because when you drop the merely good parts, the great parts can shine more brightly.
It’s easy to overdo it with premature planning, fine-tuning, and RAG
Until there is proven value from such efforts, better to keep it simple
Context is everything
Agents are tool-driven. Without tools, they cannot do anything and even if you had a super advanced orchestration loop, it wouldn’t help.
High quality tools are the bread and butter of effective agents
Emulate a real chat. All context interactions have to account for the fact that models are trained on chat and work best with realistic chat messages.
As an example, some tools might produce no output, which is an open invitation to hallucinate. Handle special cases so that they produce a coherent chat history.
Every token matters
Some time ago, we expected that as models got better, they would be less sensitive to minor token variations in prompts.
It doesn’t seem like this problem has solved itself yet. We still encounter cases where single tokens make or break a scenario. As an example, the difference between singular and plural Contact -> Contacts is enough to produce the wrong table name in tests.
Reduce the noise - Any token can potentially throw off the LLM
As before, you will want to triple check every single token that makes it into your context, and only include those that add value.
Make sure your prompts are as distilled and concise as possible. Adopt a zero-tolerance stance towards grammar mistakes and typos.
LLMs increasingly depend on free-text data like names and descriptions. Ensure this data is of high semantic quality, and not too complex.
Rule of thumb: If it doesn’t make sense to you, it won’t work for the LLM.
This may also apply to localizations!
Allow the LLM to focus on what it’s good at
If possible define data at design time rather than relying on LLM to re-generate Guids, etc.
Over-Anthropomorphization
The language used to describe LLM-backed products is too close to human semantics
This leads to expectations that go beyond merely predicting the next token
We tend to use human verbs like think, know.
Agent is a bad term that inspires human analogies. An alternative is to consistently use bot or LLM-bot instead as this more clearly communicates expectations to users.
There is no brain / memory / thought / knowledge.
Simply put, if critical data is missing from the context, then it is very unlikely that the LLM will predict the correct tokens.
While GPT-4o does seem to be the best model on average, it is not significantly outperforming GPT-4 (0613), which at this point is over a year old.
Think back one year and what expectations we had back then for where we would be by now. Given how quickly GPT 3.5 and 4 dropped, people were led to believe that we would have some truly amazing next version by mid-2024.
New models are different, not just better
While we did get many new models (gpt 4 turbo and now 4o), it’s not entirely clear whether they are improvements across the board
Ultimately there hasn’t been any groundbreaking improvement in LLM output quality since GPT 4.
While we can expect to eventually get GPT 5 or the like (much better?), we are still constrained by COGS, which are likely higher. So we may want to explore SMLs, etc., and alternative approaches to improve
Initially, I was doubtful whether this was the best choice for a great Onsen experience in Japan.
Most reports I read didn’t praise it too highly and generally dedicated little time to it.
Beppu turned out to be my favorite place this time and I ended up pulling in extra days to extend my stay here.
I highly recommend going if you enjoy onsen, as there is a lot of variety, and it’s a great place to relax.
I’ll showcase a few of my favorite places below.
Yuyama no Sato 湯山の里
This onsen village lies just behind Myoban (明礬), so I kind of count it into the same area.
After a quick checkin with the owner, who built the entire place himself, there’s a small 5 min hike through a small bamboo forest, down to then onsen.
Since we didn’t meet anyone else here, this would be my secret tip.
There is an abundance of different pools, with the temperature on the hotter side.
Ebisu 湯屋えびす
Located in Myoban (明礬). They have both shared and private baths.
Nabeyama 鍋山の湯
There are a few free onsen pools in the mountains a small hike away from Myoban (明礬).
The water wasn’t quite warm enough when I got there, so it can be hit or miss, but the hike is nice and the views good, too.
Kannawa 鉄輪温泉
Cozy little district with steam coming out of the ground everywhere.
Cats chilling, sometimes hiding their head in a crack in the ground to keep warm.
Tons of small ~100¥ Onsen which make it fun to hop from one to the other.
Shibaseki 紫関温泉
Don’t have any pictures of this one, but very worth a visit.
They have a very hot indoor pool, a relaxing outdoor pool, and an amazing sauna!
The locals are super fun here :)
Suginoi area
This refers to the south-western part of Beppu, where the Suginoi Hotel is located.
Since these places are closely located, I group them under this moniker.
Horita 堀田温泉
Mugen no Sato 夢幻の里
Consists of multiple private onsen, which you can rent for 1h for very little money (I think 1000?).
You can also steam your own food here, using the steam from the water.
Recommend to capitalize on this and bring lots of raw ingredients.
Things like Kabocha turn out great.
Suginoi Hotel 杉乃井ホテル
This hotel has a rooftop outdoor pool area for swimming (heated) and an onsen area with amazing views over the Beppu bay.
Suggest to time your visit for sunset and enjoy the evening here.
For this post I want to record some of my first impressions of LLMs and prompting, as well as some of the insights I believe to have gained. It will be interesting to revisit this later on and see how it held up.
The intersection of programming and language
I anticipate a new paradigm at the intersection of programming and language understanding.
LLMs are now capable enough so that software engineers can take off-the-shelf models and build applications with them. In order to instruct the model, prompts are written in natural language, just like the outputs. The hurdle of data science is no longer.
Anyone can write such prompts, but to truly develop reliable, effective prompts, it seems to me one has to develop an understanding and intuition about the way the LLM speaks and comprehends language.
At the same time, it’s not enough to just be good at prompting. One also needs a methodical approach to evaluate the results of the model. This is where programming concepts like unit testing come in handy. If you want to take your prompts to the next level, find a metric that measures the output quality, then apply TDD (Test Driven Development) to push the prompt to its limits, by continuously testing and refining.
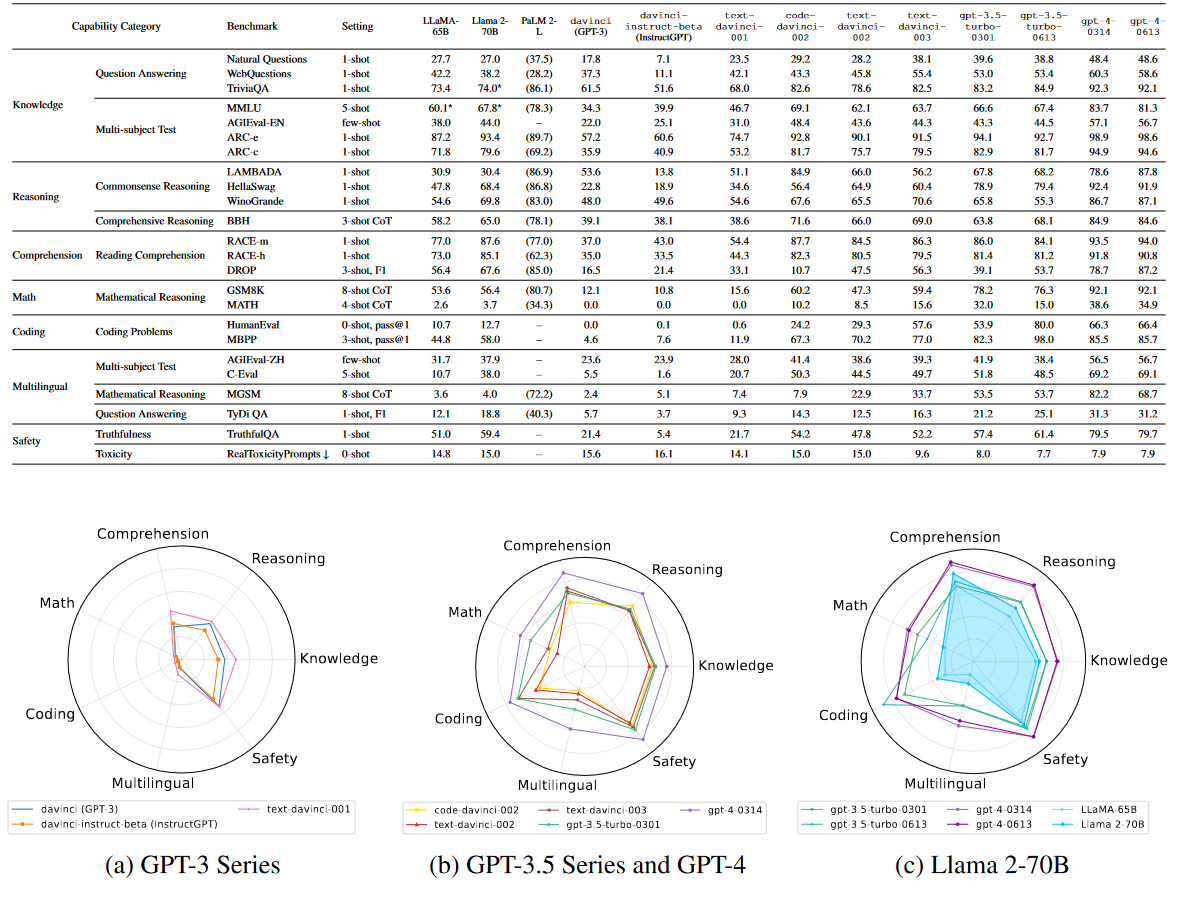
This is already being done at the model level, yielding the below chart, which can help visualize the strengths & weaknesses of each model.
Once you’ve tried to combine plain programming with LLM prompts, you might agree with me that this is the next big step for our industry.
I recommend this Latent Space episode, which coins the term AI Engineer to define software engineers moving closer to the ML space to get enough proficiency to effectively apply LLMs to produce new applications.
Distilling prompts
The art of prompting is still in its infancy and no exact science. I don’t claim to have all the answers, but the following has worked well for me.
Most of this applies to GPT 3.5 0613
Primarily targeting Reductive Operations, such as Summarization and Extraction
When writing prompts, I have observed the following tendencies.
Less is more
You are like this tea cup, so full that nothing more can be added. Come back to me when the cup is empty. Come back to me with an empty mind.
Laozi
Being overly prescriptive, wordy, and detailed.
Lots of rules, and when something doesn’t quite turn out how we want it to, we add another special case sentence. The prompt ends up overloaded so that any single change, formatting or content, breaks it. In such cases it is better to go back to zero, and come back witn an empty mind / prompt.
Try to distill your prompt down to the most essential meaning. Every single word in your prompt matters, and there should be a reason for why you include it.
Just like we do with language and code, in order to really convey our intent, we distill our prompt down to its essence.
Distillation is at the very heart of all effective communication. The more important it is that your audience hear and take action on your message, the more distilled that message needs to be.
Building a Second Brain by Tiago Forte
Lastly, it’s worth noting that the same meaning phrased differently can lead to radically different results. So rather than throw more words at it, I prefer to find few words which trigger the right response.
Forcing the model …
… to do something it isn’t good at.
Outputting JSON or producing answers that require non-language thinking.
Instead of trying to control the output with rules and confusing the model with complex instructions where even we have to think, I found that starting out with a highly distilled version (as little as a single sentence) can shed some light on what the model is good at natively.
So rather than trying to bend the model to your will, try to cooperate!
I found that oftentimes you don’t have to instruct 3.5 about the output format at all. It tends to produce colon-delimited key-value pairs if only you change your wording slightly. Provide X, Y, Z ... seems to work well, where XYZ are properties that start with a captial letter.
You can save yourself lots of trouble by simply going with the flow of whatever the LLM is comfortable with.
Native code intuition
GPT 3.5 seems to have very good intuition about coding concepts. As software engineers, this gives us superpowers, as we can boil down complex intent into sometimes single characters.
As an example, if you use extraction prompts like the above, you can easily communicate that you want certain properties to be nullable/optional: Provide X, Y?, Z .... Just by appending ? to the property, the model will often prefer to omit rather than invent outputs.
Language efficiency
One other thing I observed is that English is a pretty good language for prompts. Usually one of the drawbacks of English is that it requires a lot of characters compared to languages like Chinese.
Twitter used to have a really low character limit per tweet, which was easily consumed in “western” languages. Character-based writing systems can simply fit more meaning into a single tweet. It’s part of the reason why Musk stated that Twitter’s ideal market isn’t the U.S.—it’s Japan (behind paywall but you can sidestep with reader). I explore some of the reasons why Japanese is more concise in Language features across the boundary.
However, what matters in prompts are tokens, not characters, and from my experience the tokenization of English is quite efficient. A lot of words are encoded as a single token, which means they can compete with Chinese characters.
Outro
The above is just a snapshot of my current ideas. Excited to see where things are at in a few months. Currently reading Building a Second Brain by Tiago Forte, and it is amazing how much of it applies to LLMs / prompting.
[…] if you’re stuck on a task, break it down into smaller steps.
As you distill your ideas, they naturally improve, because when you drop the merely good parts, the great parts can shine more brightly.
Similar to what I wrote about distillation above.
Lastly, I found this example from the book very interesting:
Coppola’s strategy for making the complex, multifaceted film rested on a technique he learned studying theater at Hofstra College, known as a “prompt book.”
Coppola considered the prompt book that emerged from this process the most important asset in the production of his now classic film: “the script was really an unnecessary document; I didn’t need a script because I could have made the movie just from this notebook.”
Basically Coppola was prompting himself with this book, which enabled him to produce The Godfather without the full script. Sounds like he had enough training data :)
There are many techniques of varying sophistication to achieve clean cross cutting concerns. Let’s walk through some of them and discuss their pros and cons.
This post mostly serves as a reference for myself, to gather my thoughts. I won’t bother with implementation details and sample code may not compile.
Scenario
Imagine we have a repository that fetches weather data from a database.
It could look similar to the below, but assume many more methods.
We will evaluate the techniques based on the following requirements:
We don’t really care about the implementation, but we want to start applying some caching to avoid repeated database calls, as we have a lot of read requests coming in and the data won’t change for some time.
Bonus points for not needing to duplicate the caching code in each method.
Initially we can use a memory cache, but later we might want to switch to a distributed cache.
Bonus points for least amount of changes needed to switch the caching implementation.
We want to apply other cross-cutting concerns to the repository, like logging.
Bonus points for ease of extensibility and maintainability.
Lastly, we want to be able to test the repository without caching and logging.
Techniques
Simple approach
Often the first approach that comes to mind is to inject a cache and add the caching logic to each of the methods.
It might seem simple at first, but once you start applying this at scale, you will quickly realize that this is not maintainable. Think about tens of repository classes, each with tens of methods.
Dynamic dispatch
By overriding the methods in our repository, we can achieve separation of concerns between the business logic and the caching.
Now we have a semi-central place for caching, although it still has to be duplicated per repository class. We also still have to duplicate the caching logic in each method.
Note that this requires the methods to be virtual. We can work around this limitation with the decorator pattern.
Given n repositories, and m cross-cutting concerns, we would need n * m subclasses. Simple code, but not maintainable.
Query pattern
This approach combines several patterns to achieve high flexibility.
The central idea is to treat any request to the database as a query object, which is passed to an executor. Contrary to their name, these query objects actually implement the command pattern, meaning they encapsulate a set of instructions that can be defined separately from their execution.
Usually, you will have some interface like this at the top level:
interfaceIQuery<T>{TExecute();}
Important is that these queries can be newed without any dependencies. We can then isolate the query specification / construction by using a factory. The concrete implementation depends on your database.
Using the decorator pattern, we can wrap the core query logic with additional behavior.
Combining this, you will end up with something like this:
publicclassQueryWeatherRepository:IWeatherRepository{privatereadonlyQueryExecutorqueryExecutor;privatereadonlyQueryFactoryqueryFactory;publicWeatherForecastGetForecast(){varquery=queryFactory.BuildForecastQuery().UseCaching()// extensions that leverage the decorator pattern.UseLogging();returnqueryExecutor.Execute(query);}
No subclassing, no virtual methods, no need to duplicate the caching or logging logic.
A downside is that you have to think and come up with a setup for this.
Let’s check off the requirements:
No duplicated caching logic
Switching caching implementation only touches a single class (caching decorator)
We can add any cross-cutting concern by adding a decorator
We can test the queries independently
One more thing to observe is how our code becomes much more declarative and high level. Our repository no longer dishes out specific, brittle instructions. Rather, we specify the behavior we would like to see and rely on the framework to execute it.
Aspect Oriented Programming (AOP)
Although I haven’t had a chance to try AOP in C# yet, I am familiar with AspectJ and Spring AOP.
PostSharp is similar to Spring, with the main downside that it is commercial. We can add caching with a few attributes:
This is easily the cleanest approach, requiring the least amount of code. You can add more behavior like logging or retry simply by adding the corresponding attributes.
It feels like magic, which is sometimes claimed to be a bad thing. I for one believe AOP is a true boon to software development. One downside is the framework buy-in.
Even if you don’t use AOP in your daily work, I still highly recommend learning about it on your own time. It gives you a new perspective that will help you identify and solve architectural problems in your code.
In particular, I found this course to be a great learning resource:
The best (and most) hot springs are, no doubt, in onsen-country, Japan ♨️. However, there are still worthwhile alternatives in sometimes unexpected locations that I would recommend checking out. So instead of covering some of the famous onsen towns of Japan, let’s talk about some of the lesser-known options.
In particular, I am very fond of 海中温泉, meaning hot springs in the ocean. These hot springs developed naturally on the coast, which makes them quite unique.
Yakushima
This small island south of the Japanese mainland is one of my favorite places in Japan, not least because of its amazing hot springs!
The Hirauchi Kaichuu Onsen - 平内海中温泉 lies at the coast of the island and its basins are filled with ocean water. It’s basically free, but you are encouraged to donate a few hundred yen to the locals maintaining it.
One of the coolest experiences is to come here in the night and enjoy the starry sky whilst taking a hot bath. There are various temperatures to choose from in the basins, but a little caution is required as some can get very hot.
We were here at the end of the year and the weather was amazing. Moderate temperature, sunny sky, tasty local produce like Ponkan, superb nature, and hot springs in the night made Yakushima one of my favorite destinations.
Ischia
Ischia is an island off the coast of Napoli in Italy.
It’s a popular tourist destination and unfortunately we made the mistake of coming here during the summer, meaning it was very crowded and our overall experience wasn’t the best.
Besides some negative experiences, what saved the trip was our discovery of a hot spring in the ocean in the island’s southern part.
Baia di Sorgeto is a little more difficult to access, but worth it every time. We spent every evening here. As it is entirely natural, this onsen is also free. There are a number of other (commercial) hot springs on the island, but they were all closed due to Covid. Even so, I felt the trip was worth it because Baia di Sorgeto was outstanding.
São Miguel
In the middle of the atlantic ocean lie the Azores, a group of Portugese islands, the biggest of which is São Miguel.
I decided to visit because of the many similarities to Japan / Yakushima: A volcanic island with lush, green vegetation, warm but rainy weather, tea plantations, and of course hot springs ♨️.
It’s a bit difficult to get here, as there aren’t many international flights, so the most likely route is via Portugal’s mainland.
Anyway it’s worth the effort, as this island has so much to offer.
Caldeira Velha is like a little trip through the jungle, with hot springs along the way. Although there is only one smaller basin with really hot water, it’s a very atmospheric and relaxing journey.
Then there is Termas das Caldeiras, a smaller hot spring bath. We put this one off because it seemed too small from the reviews. In the end we did have an opportunity to try it, and it became one of our favorite experiences. The pools are small but we were lucky that there were few people and at some point we were even alone. Later on someone performed a few songs on a handpan. This was the best meditative atmosphere in any hot spring here. This place also has probably the hottest pool available.
There is also an onsen in the sea, but we had no luck with the tide, so the water wasn’t warm enough. This hot spring goes by the name Ponta Ferraria, but it’s a little further away from everything so we didn’t try again.
Furnas
Then there is the little onsen town Furnas. I recommend staying here to maximize your time in the hot springs. Furnas is quite popular among locals and tourists, so expect a lot of traffic. Therefore, it’s better to be close by and flexible so that you can time your visits and spend extended time in the hot springs without having to worry about getting back home.
First up, the Poça da Dona Beija, which consists of several medium-size pools of depth. Definitely check it out, but be aware that it gets busy towards the evening.
The main attraction is Parque Terra Nostra, which is a botanical garden with several hot spring baths included. One of these is actually a gigantic pool in which you can swim freely.
The park itself is well worth seeing, but that onsen pool is truly a rare sight to behold! It’s extremely satisfying to swim in the thermal water and you can find temperature differences throughout the pool.
Outside Japan, hot spring temperatures are usually lower and you rarely encounter foot-onsens, i.e. hot springs which you put your feet into. Furnas actually has one of those! It’s called Poça da Tia Silvina, and it’s exceptionally hot. This foot onsen it located on the river bank in Furnas and is free. Recommend to grab some desserts from the Glória Moniz bakery and come down here to relax. Might have to bring an umbrella :)
Lastly, they also make food with the thermal heat, which results in a dish called Cozido das Furnas. This is definitely worth trying! Amazing to see the many use cases thermal heat can fit into.
Conclusion
Hot springs are amazing and I wish they could be found anywhere. In recent years I found a few hot springs that can make up for their general absence throughout Europe. I hope to visit many more in other parts of the world.
Flows are a great tool for automation and integration, but whilst the low/no code paradigm aims to make programming more accessible, it also introduces some pitfalls that are not immediately obvious to both casual and professional programmers.
Performance is a frequently problematic area, as the restricted Flow development environment makes it hard to see why things are slow and doesn’t provide many options to address the issues.
Control
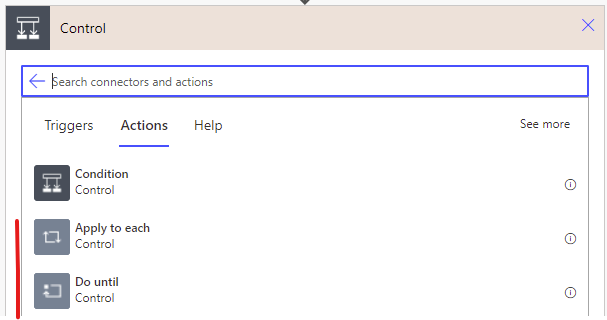
One issue I’ve seen come up again and again in Flows is the use of imperative iteration.
In other words, the two control actions Apply to each and Do until. At first glance, they seem like the go-to actions for looping.
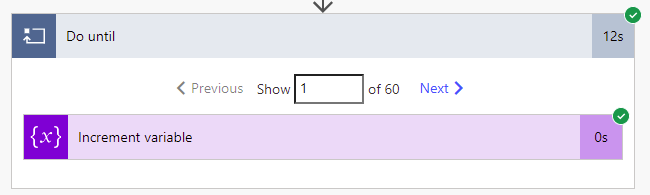
Turns out you are better off avoiding them unless absolutely necessary, seeing as the performance is abyssmal. Consider this simple, bare-bones Do until, with a single action to increment an integer inside:
60 iterations took 12 seconds! This is completely unexpected for someone coming from traditional programming.
When using these control actions, what you’d likely expect to happen behind the scenes is something like the following:
while(i<60){i++}
This should take mere nanoseconds, so how come it took 12 whole seconds in the Flow?
There is significant overhead associated with each iteration, leading to long durations and potential timeouts. Unlike a traditional while or for loop, the control actions spawn a sub process for each iteration.
Now imagine running this with 1000s of iterations. You can freeze your whole system if you’re not careful here.
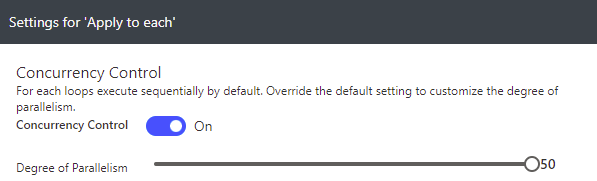
As you can see, simple loops are very counter-intuitive in Flows. In order to rectify the situation, oftentimes the concurrency is upped. This does lead to faster execution, but increases the load on the system and can impact quota usage. Besides, you’ll hit the max eventually.
Surely, there’s gotta be a better way, right? After all, loops are such a fundamental part of any program.
Data Operations
The antidote to the Control loop slowness comes in the form of Data operations.
Data operations are to control loops as declarative programming is to imperative. They are basically higher order functions.
Let’s see some quick examples as proof of their speed.
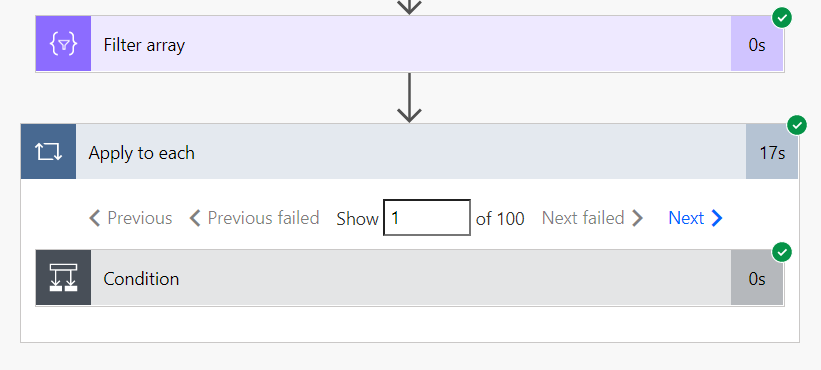
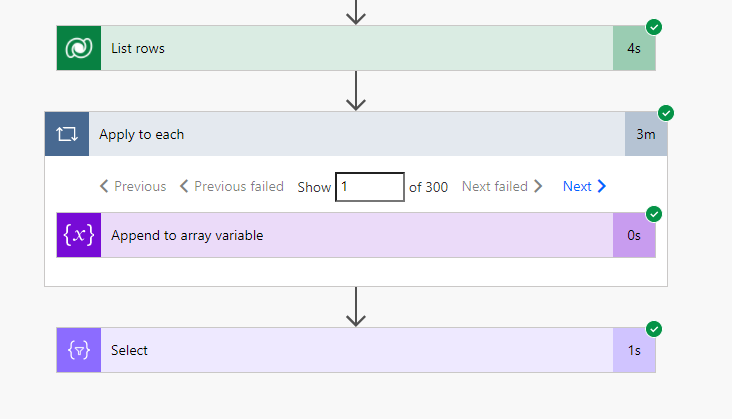
Select
One example could be the transformation of a set of row objects to an array of their ids. The imperative Apply to each loop takes ~3 minutes for 300 records, even though the individual append operation takes less than a second. The functional Select operation completes within 1 second.
Filter
Looping over 100 items, even without any logic in the condition, takes a significant amount of time.
The functional Filter array operation completes in less than a second, as we would expect from such a workload.
As we can see, data operations have the performance characteristics which we originally expected to see form the imperative approach.
There is hardly ever a reason not to use them, as long as the functional outcome is the same. One area that cannot be covered is the integration with external systems. Making a call to a system that expects a single data record cannot be optimized.
If you own the API, you can attempt a batch approach instead of one-by-one calls, and parse the data with data operations.
Change of approach
As with the transition from imperative to functional, a different mindset is often required to effectively utilize data operations.
I encourage you to leave complex control structures and mutation behind, and instead focus on pure, higher-order functions processing collections rather than single records.
The best way to learn is to take up languages that naturally promote functional concepts. Although most mainstream languages support higher order functions by now, I personally learned a lot from diving into Kotlin, which I believe is the perfect bridge between imperative OO and functional.
Conclusion
As a general guideline: Avoid looping over arrays of even medium size (100s). Prefer data operations like Select, Compose, Join, Filter to manipulate and transform multiple records at once. (Analogous to functional > imperative in OO)
Reserve the control loops for situations where data operations cannot be used.
In western languages we are used to repeatedly re-declare the topic we are talking about. There is hardly a sentence without a pronoun, and we often have to find creative ways to reduce repetition, in order not to sound dry and robotic.
Imagine a typical conversation between person A and B:
A:How is your new teacher?B:I don't like him. He's too strict.A:Is he worse than Mr. X?B:No, but he still thinks it's the 80s....
This could go on for quite a bit, but after the first sentence it should be clear to everyone what the topic is. Then why do we have to repeatedly refer to it?
Think about introducing yourself to an audience. Nobody is in doubt who you are talking about, yet practically every sentence will contain an I or my.
Growing up with such a language, this feels normal. Although, as developers, we tend to get an allergic reaction when seeing excessive repetition.
Once we discover an elegant alternative, we realize that languages like English, German, Danish are really quite verbose. They are said to be subject-prominent.
Topic markers
Some natural languages, like Japanese and Korean, support a feature called topic markers. They allow you to declare a topic, and then largely omit referencing it throughout the conversation.
Going back to the previous example, once the topic is established, we can stop referring to it.
A:How is new teacher?B:Don't like. Too strict.A:Worse than Mr. X?B:No, but still thinks it's the 80s....
This sounds unnatural in English, but is the default in Japanese. In fact, we can omit nearly all pronouns, as they are usually inferred from the context:
When A asks B a question, B is not in doubt whose teacher A is talking about.
When B states her opinion, both know who about.
As long as the topic doesn’t change, there is no need to refer to the teacher with pronouns.
Implicit topics
Context-heavy languages assume a lot of implicit information, allowing for very succinct communication. Japanese is known for being on the extreme end of the context-heavy scala, as almost every sentence will omit some information.
In high context cultures many of the words you might think of as essential in another linguistic setting become unnecessary or out of place. Japanese is one such language, where things are often implied by context and mutual understanding.
A classic is the sentence 僕はウナギだ, which can be interpreted as I am an eel, which doesn’t make much sense. The implicit context is that we are in a restaurant, where the sentence is used to state your order, as in I'd like the eel, please.
More generally, you omit pronouns in most conversations. When talking about yourself, stating your thoughts, or telling a story about your kids, you won’t have to say I / my. Once you open your mouth, it is clear that you are the topic. When seeing a colleague and asking a question, you won’t say You. The other person understands that he is the one being asked.
Once I went to a book store, where a band was playing. Just as I entered, they stopped playing, and I went up to one of the members to ask whether they would continue later. The entire conversation was:
Me:もう終わった?# ~ Already finished?He:まだ。# ~ Still.
I was taken aback by the curtness of his answer, but this is really quite common.
Programming analog
The first similar concept that comes to mind is a plain class, from which we can reference other members of the class without qualification.
As mentioned, in Japanese you can omit declaring yourself as the topic. Let’s imagine a class about ourselves, called I.
classI{privatefunthink(about:String){}funsay(){think("No more subject!")think("Context is awesome!")}}
As opposed to:
vali=I()funsay(){i.think("therefore I am")i.think("repetition is boring")}
Generally, good design will produce classes with low subject repetition. Similar to how we organize our prose to minimize repetition and keep the reader engaged. If we find ourselves frequently referring to the same subject, then that is a sign that the code belongs in a (topic) class.
This works well when we own the class, but what if the topic is out of our control?
Extension functions with receivers
Have you ever had to write a function which operates on an external type, like the below?
funmutate(external:External){external.name="Test"external.age=10_000external.location=getCurrentLocation()external.status=...external.yetAnotherField=.../// 10 more fields to set}
This is super annoying. We basically want a way to declare external as our topic, and then stop referring to it in every single line, as if it was a function of the class itself.
In Kotlin, extension functions are declared by defining a receiver type for the function. Within its scope, the receiver becomes this, and can be omitted.
Such receivers can be thought of as topic markers, indicating that the following block of code will invoke the topic without explicitly referencing it.
The standard library contains generic helper functions, like apply to facilitate this inline.
StringBuilder().apply{append("Hello ")names.forEach{append(it).append(",")}setLength(length-1)append("!")}.toString()// Hello A, B!
Without apply, we would have to declare the subject in every line, sometimes even twice. We could actually create a similar helper for the Japanese topic marker は:
Another cool thing here is the notion of nested receivers / topics, just as in natural language. The textColumn only makes sense in the context of a form in a body in html.
Going back to the eel example, how could we express this in code? First, we can always assume an implicit context of I. Next, we are in a restaurant and, facing the waiter, it is clear that we intend to order food.
classI{funRestaurantOrder.unagi()=order(Menu.EelOnRice,1)}I{// implicit Irestaurant{// when in restaurantorder{// when about to orderunagi()// when in the right context, a single word is sufficient}}}
Notice that we can define local extensions! This really allows us to express the concept of sub-topics, i.e. the unagi restaurant order only applies to me.
Further parallels
In Japanese, adding back the omitted subject references still leads to grammatically correct sentences, but they will be perceived as awkward, and you will have trouble making yourself understood. This is analogous to unclean code with excessive duplication, or unnecessary qualifications. For others reading your code, this noise is an impairment to understanding your true intent.
Conclusion
In programming, topics are generally handled by defining classes of cohesive members, which can operate on the topic without explicit references. Kotlin adds the magic by allowing the same behavior on external types via extensions. Bonus points for local extensions!
Natural languages like Japanese have a special topic marker particle which feels similar to defining the receiver on an extension function. In context-heavy languages we can omit a lot of implicit information, often leading to much shorter, concise sentences.
To me, both Kotlin and Japanese have a sense of elegance, as it is super easy to produce highly expressive and concise output.

 614 MB
614 MB







 This is bicarbonate water.
This is bicarbonate water.
 It’s a nice, scenic path from the shuttle to the onsen.
It’s a nice, scenic path from the shuttle to the onsen.
 The cuisine has strong influences from neighboring Thailand and Myanmar, often incorporating fruit. I am especially fond of anything with passion fruit. I had both a hotpot with passion fruit in the soup, and amazing local tomatoes with passion fruit dressing.
The cuisine has strong influences from neighboring Thailand and Myanmar, often incorporating fruit. I am especially fond of anything with passion fruit. I had both a hotpot with passion fruit in the soup, and amazing local tomatoes with passion fruit dressing. There are some fruits here that I have never tried before, and unfortunately don’t know the name right now.
There are some fruits here that I have never tried before, and unfortunately don’t know the name right now. I really enjoyed the local coffee and the surrounding culture. It reminds me a bit of Italy.
I really enjoyed the local coffee and the surrounding culture. It reminds me a bit of Italy.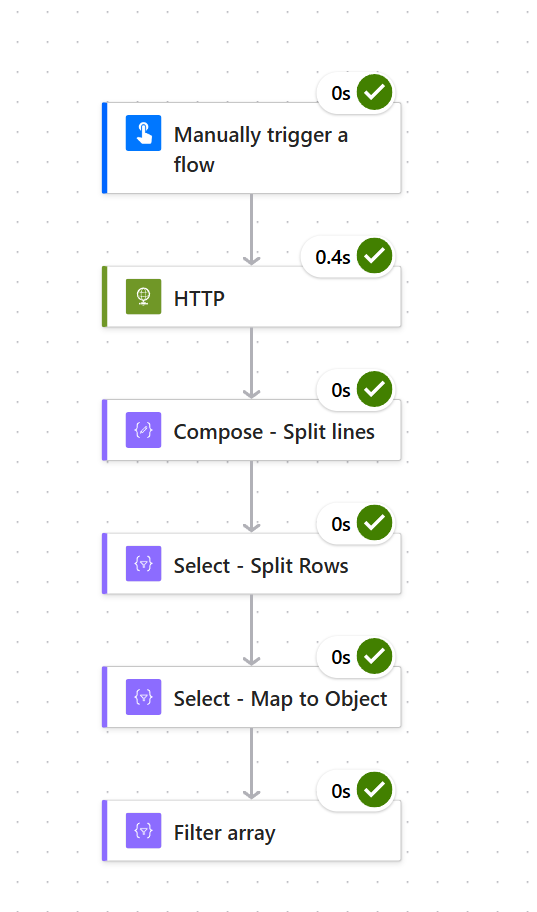




















 This hot spring goes by the name Ponta Ferraria, but it’s a little further away from everything so we didn’t try again.
This hot spring goes by the name Ponta Ferraria, but it’s a little further away from everything so we didn’t try again.
 Besides, you’ll hit the max eventually.
Besides, you’ll hit the max eventually.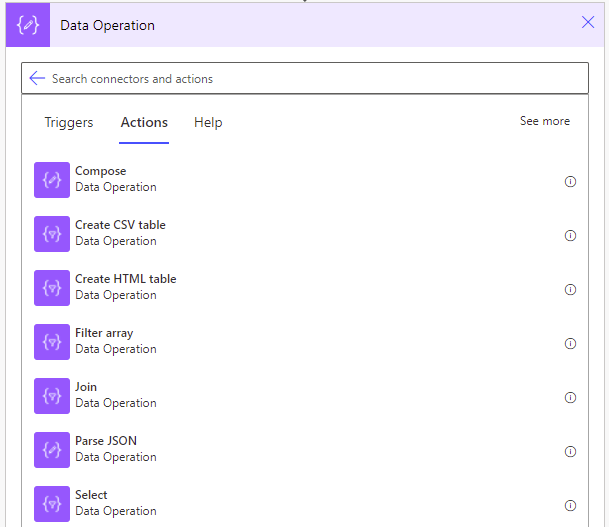
 The imperative
The imperative