Dataverse Performance - Flow Iteration
in Blog
Flows are a great tool for automation and integration, but whilst the low/no code paradigm aims to make programming more accessible, it also introduces some pitfalls that are not immediately obvious to both casual and professional programmers.
Performance is a frequently problematic area, as the restricted Flow development environment makes it hard to see why things are slow and doesn’t provide many options to address the issues.
Control
One issue I’ve seen come up again and again in Flows is the use of imperative iteration.
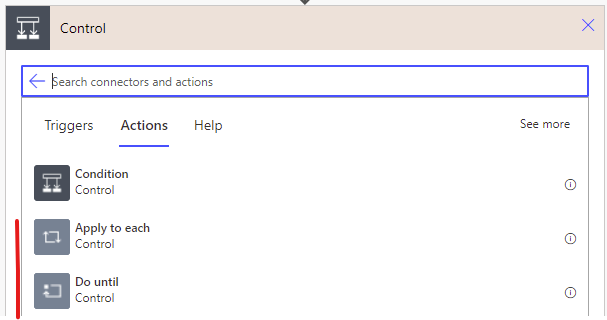
In other words, the two control actions Apply to each and Do until.
At first glance, they seem like the go-to actions for looping.
Turns out you are better off avoiding them unless absolutely necessary, seeing as the performance is abyssmal.
Consider this simple, bare-bones Do until, with a single action to increment an integer inside:
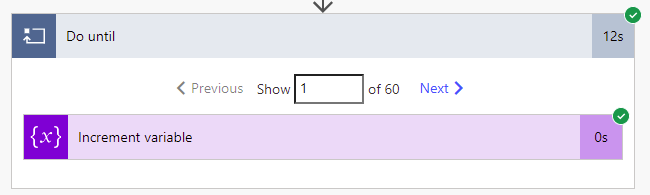
60 iterations took 12 seconds! This is completely unexpected for someone coming from traditional programming.
When using these control actions, what you’d likely expect to happen behind the scenes is something like the following:
while (i < 60) {
i++
}
This should take mere nanoseconds, so how come it took 12 whole seconds in the Flow?
There is significant overhead associated with each iteration, leading to long durations and potential timeouts. Unlike a traditional while or for loop, the control actions spawn a sub process for each iteration.
Now imagine running this with 1000s of iterations. You can freeze your whole system if you’re not careful here.
As you can see, simple loops are very counter-intuitive in Flows.
In order to rectify the situation, oftentimes the concurrency is upped.
This does lead to faster execution, but increases the load on the system and can impact quota usage.
Surely, there’s gotta be a better way, right? After all, loops are such a fundamental part of any program.
Data Operations
The antidote to the Control loop slowness comes in the form of Data operations.
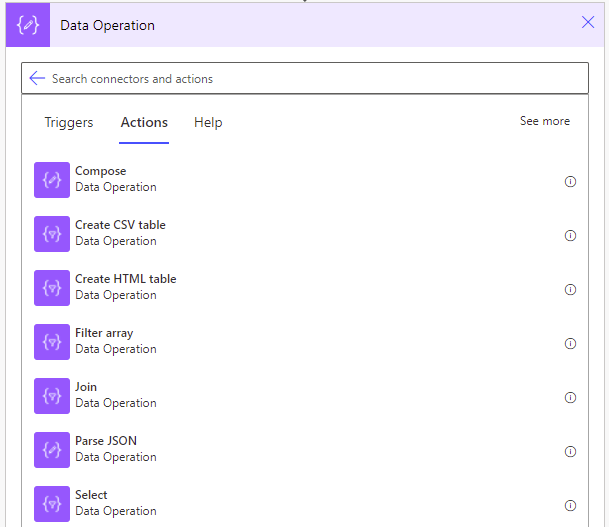
Data operations are to control loops as declarative programming is to imperative. They are basically higher order functions.
Let’s see some quick examples as proof of their speed.
Select
One example could be the transformation of a set of row objects to an array of their ids.
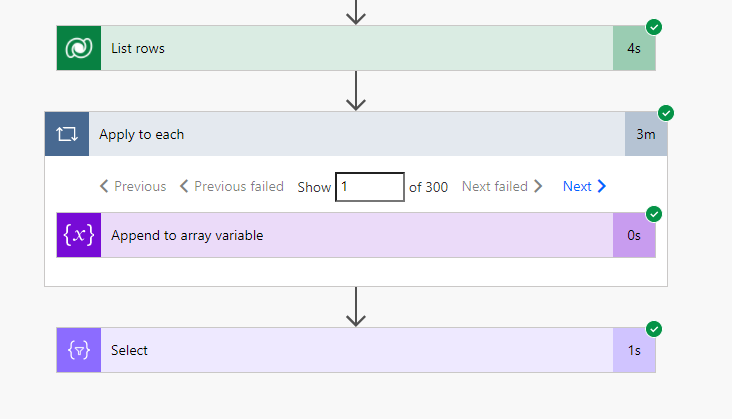
Apply to each loop takes ~3 minutes for 300 records,
even though the individual append operation takes less than a second.
The functional Select operation completes within 1 second.
Filter
Looping over 100 items, even without any logic in the condition, takes a significant amount of time.
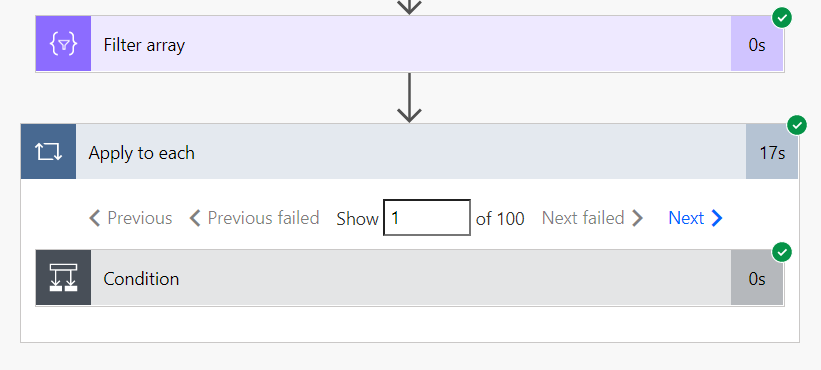
The functional Filter array operation completes in less than a second, as we would expect from such a workload.
As we can see, data operations have the performance characteristics which we originally expected to see form the imperative approach.
There is hardly ever a reason not to use them, as long as the functional outcome is the same. One area that cannot be covered is the integration with external systems. Making a call to a system that expects a single data record cannot be optimized.
If you own the API, you can attempt a batch approach instead of one-by-one calls, and parse the data with data operations.
Change of approach
As with the transition from imperative to functional, a different mindset is often required to effectively utilize data operations.
I encourage you to leave complex control structures and mutation behind, and instead focus on pure, higher-order functions processing collections rather than single records.
The best way to learn is to take up languages that naturally promote functional concepts. Although most mainstream languages support higher order functions by now, I personally learned a lot from diving into Kotlin, which I believe is the perfect bridge between imperative OO and functional.
Conclusion
As a general guideline:
Avoid looping over arrays of even medium size (100s).
Prefer data operations like Select, Compose, Join, Filter to manipulate and transform multiple records at once.
(Analogous to functional > imperative in OO)
Reserve the control loops for situations where data operations cannot be used.