⚗️ Distilled knowledge
in Blog
For this post I want to record some of my first impressions of LLMs and prompting, as well as some of the insights I believe to have gained. It will be interesting to revisit this later on and see how it held up.
The intersection of programming and language
I anticipate a new paradigm at the intersection of programming and language understanding.
LLMs are now capable enough so that software engineers can take off-the-shelf models and build applications with them. In order to instruct the model, prompts are written in natural language, just like the outputs. The hurdle of data science is no longer.
Anyone can write such prompts, but to truly develop reliable, effective prompts, it seems to me one has to develop an understanding and intuition about the way the LLM speaks and comprehends language.
At the same time, it’s not enough to just be good at prompting. One also needs a methodical approach to evaluate the results of the model. This is where programming concepts like unit testing come in handy. If you want to take your prompts to the next level, find a metric that measures the output quality, then apply TDD (Test Driven Development) to push the prompt to its limits, by continuously testing and refining.
This is already being done at the model level, yielding the below chart,
which can help visualize the strengths & weaknesses of each model.
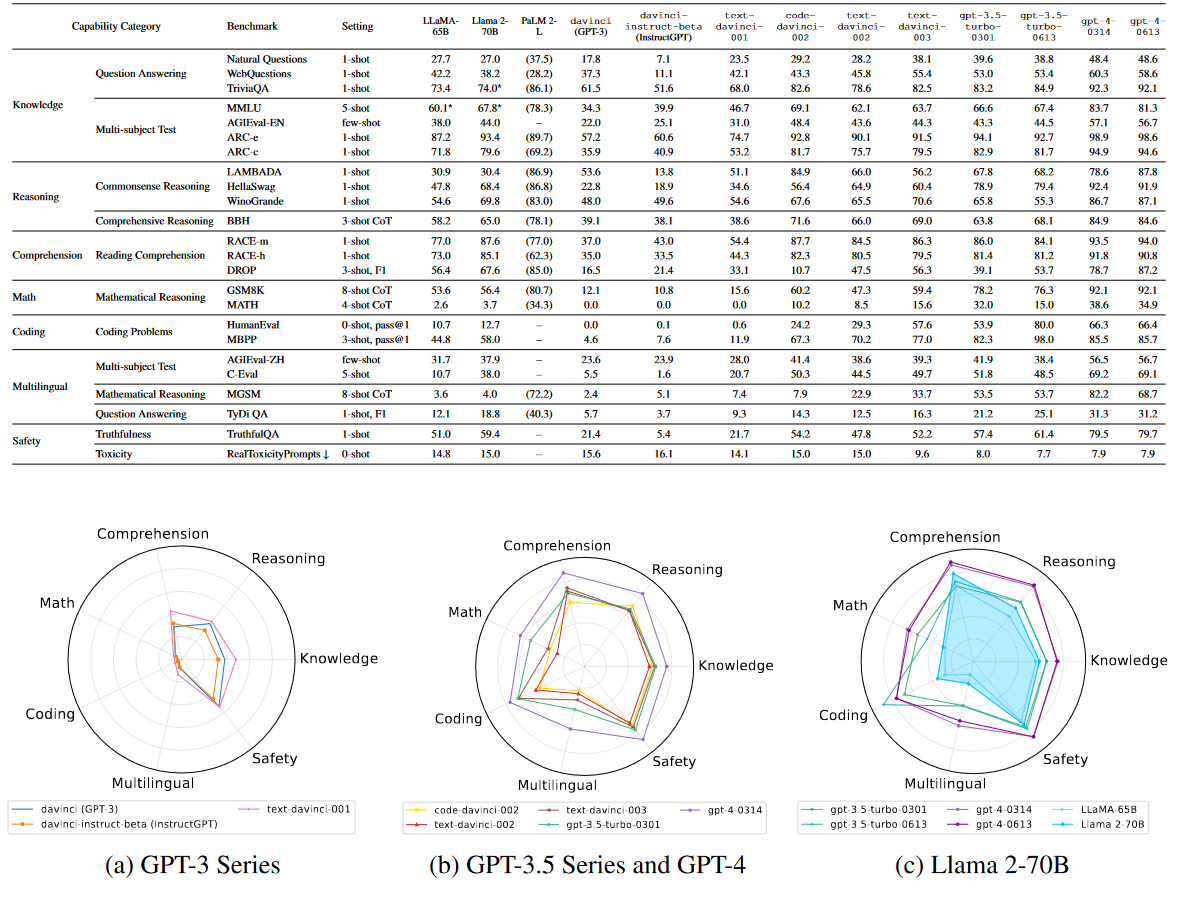
Once you’ve tried to combine plain programming with LLM prompts, you might agree with me that this is the next big step for our industry.
I recommend this Latent Space episode, which coins the term AI Engineer to define software engineers moving closer to the ML space to get enough proficiency to effectively apply LLMs to produce new applications.
Distilling prompts
The art of prompting is still in its infancy and no exact science. I don’t claim to have all the answers, but the following has worked well for me.
- Most of this applies to GPT 3.5 0613
- Primarily targeting Reductive Operations, such as Summarization and Extraction
When writing prompts, I have observed the following tendencies.
Less is more
You are like this tea cup, so full that nothing more can be added. Come back to me when the cup is empty. Come back to me with an empty mind.
Laozi
Being overly prescriptive, wordy, and detailed.
Lots of rules, and when something doesn’t quite turn out how we want it to, we add another special case sentence. The prompt ends up overloaded so that any single change, formatting or content, breaks it. In such cases it is better to go back to zero, and come back witn an empty mind / prompt.
Try to distill your prompt down to the most essential meaning. Every single word in your prompt matters, and there should be a reason for why you include it.
Just like we do with language and code, in order to really convey our intent, we distill our prompt down to its essence.
Distillation is at the very heart of all effective communication. The more important it is that your audience hear and take action on your message, the more distilled that message needs to be.
Building a Second Brain by Tiago Forte
Lastly, it’s worth noting that the same meaning phrased differently can lead to radically different results. So rather than throw more words at it, I prefer to find few words which trigger the right response.
Forcing the model …
… to do something it isn’t good at.
Outputting JSON or producing answers that require non-language thinking.
Instead of trying to control the output with rules and confusing the model with complex instructions where even we have to think, I found that starting out with a highly distilled version (as little as a single sentence) can shed some light on what the model is good at natively.
So rather than trying to bend the model to your will, try to cooperate!
I found that oftentimes you don’t have to instruct 3.5 about the output format at all.
It tends to produce colon-delimited key-value pairs if only you change your wording slightly.
Provide X, Y, Z ... seems to work well, where XYZ are properties that start with a captial letter.
You can save yourself lots of trouble by simply going with the flow of whatever the LLM is comfortable with.
Native code intuition
GPT 3.5 seems to have very good intuition about coding concepts. As software engineers, this gives us superpowers, as we can boil down complex intent into sometimes single characters.
As an example, if you use extraction prompts like the above, you can easily communicate that you want certain
properties to be nullable/optional: Provide X, Y?, Z ....
Just by appending ? to the property, the model will often prefer to omit rather than invent outputs.
Language efficiency
One other thing I observed is that English is a pretty good language for prompts. Usually one of the drawbacks of English is that it requires a lot of characters compared to languages like Chinese.
Twitter used to have a really low character limit per tweet, which was easily consumed in “western” languages. Character-based writing systems can simply fit more meaning into a single tweet. It’s part of the reason why Musk stated that Twitter’s ideal market isn’t the U.S.—it’s Japan (behind paywall but you can sidestep with reader). I explore some of the reasons why Japanese is more concise in Language features across the boundary.
However, what matters in prompts are tokens, not characters, and from my experience the tokenization of English is quite efficient.
A lot of words are encoded as a single token, which means they can compete with Chinese characters.

Outro
The above is just a snapshot of my current ideas. Excited to see where things are at in a few months. Currently reading Building a Second Brain by Tiago Forte, and it is amazing how much of it applies to LLMs / prompting.
[…] if you’re stuck on a task, break it down into smaller steps.
This aligns with the Chain-of-Thought principle for prompts.
As you distill your ideas, they naturally improve, because when you drop the merely good parts, the great parts can shine more brightly.
Similar to what I wrote about distillation above.
Lastly, I found this example from the book very interesting:
Coppola’s strategy for making the complex, multifaceted film rested on a technique he learned studying theater at Hofstra College, known as a “prompt book.”
Coppola considered the prompt book that emerged from this process the most important asset in the production of his now classic film: “the script was really an unnecessary document; I didn’t need a script because I could have made the movie just from this notebook.”
Basically Coppola was prompting himself with this book, which enabled him to produce The Godfather without the full script. Sounds like he had enough training data :)