🌐 Typing of the Dead

Learn anything with reinforcement learning and zombies
If you were young in the 00s, you may have run into the arcade light-gun game “House of the Dead” which is a rail shooter where you have to fight through zombies to survive.
I recently discovered that there is a version of this game called “Typing of the Dead” where you have to type words to kill zombies instead of shooting them.
This was sold as a tool to help people learn how to type, but I am more interested in using it for learning languages.
Therefore the question arose:
Can we hack the game to include custom vocabulary for language learning?
Installation
- Download from Abandonware
- Choose: ISO Version
 614 MB
614 MB - Use WinCdEmu to mount the
Typing of the Dead, The (Japan).cuefile - Go to the mounted drive and run
Setup.exe
Display Japanese chars in Setup
You may have issues reading the setup: 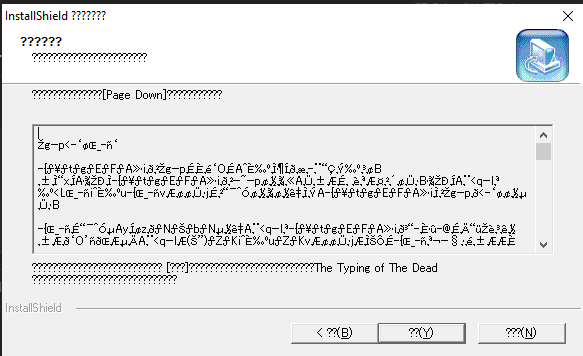
- Go to Settings > Time & Language > Language & Region
- Click Administrative language settings
- Click Change system locale
- Check Beta: Use Unicode UTF-8 for worldwide language support
- Restart your computer
Find serial
In order to install we need a serial number. I first tried the one from the Abandonware site, which is marked for the English version, but it didn’t work. After some searching I found the correct format in this thread: oshiete.goo.ne.jp/qa/252031.html.
TLDR the structure follows the pattern TODXXXXX-XXXXXX-XXXXX, where X is a digit. You can take the serial from the Abandonware site and replace the prefix.
Running the game
- Use Locale Emulator to run the game in a Japanese locale: LocaleEmulator
- Set compatibility mode to Windows XP
At this point we are ready to play: 
Out of box, the game can be used to practice Japanese, but the lack of vocab-customization means it’s not ideal for language learning.
Hacking the dictionary
The vocabulary used in the game is stored in the /word folder as .bin files.
In order to modify, we need to understand the file format.
The main structure is explained in this arcade thread by user sammargh.
In order to build the first version of the decoder, I gave Copilot the S000L010.bin file and the posts in the thread above, which, after some back and forth, resulted in correct extraction of the current vocabulary.
It then took some trial and error to figure out how to map back new vocabulary to the game, and initial attempts looked like this:

Adapt for Chinese
The game is designed for Japanese, so the engine works off Shift-JIS encoding, which means we cannot display simplified Chinese characters.
However, as a workaround, we can fallback to traditional Chinese characters.
So the phrase is the traditional version of my vocab word, and the key is the pinyin.2 version, which means 标准 -> biao1zhun3. This ensures we can easily type the keys.
Anki integration
Now naturally the next step is to integrate this with Anki, so we can use the game to practice our actual vocabulary in real time, instead of static vocab.
I already have a project where I integrate Anki with some gen AI to backfill cards which lack sample sentence, audio, or image.
To connect to Anki, I use AnkiConnect which in the current software climate feels like an Anki MCP server.
It essentially hosts a local HTTP server which exposes APIs to interact with Anki, allowing us to programmatically query, create, and modify cards.
So I just dropped my code into the project and wrote a command to find cards due today with traditional and pinyin fields populated, and then generate the .bin file from it.
Here you can see my Anki browser where the data is taken from: 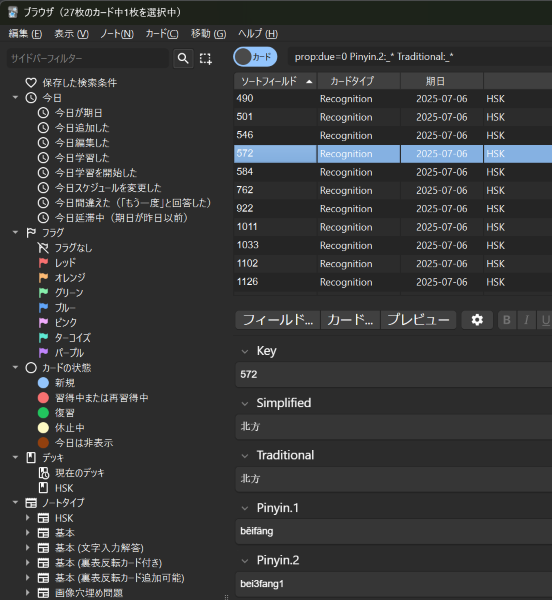
And here is the result in the game: 
All code is in github
For this experiment, I tried to rely on LLMs to speed up work. As a result ~90% of the code is written by Copilot.
The file format decoding was the hardest part, and I found that I needed a larger model like Claude Opus 4 to make sense of it.
I had to go back to Ask mode for most of the work as Agent mode does not support Claude Opus 4 and the other models produced mostly garbage.
Always optimize the context for the task at hand. In this case I needed to minimize the context to the utmost essential to prevent it from getting side-tracked.
Also see Learning from Agents - Context is Everything
Ultimately this is what the process looks like: 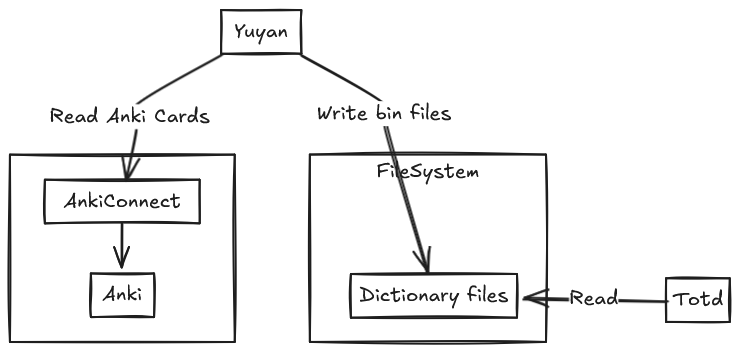
Next steps
Even though we achieved dynamic vocabulary via Anki, there are still some shortcomings that make the experience impractical:
- Ideally, we can hide the keycode so that User has to know the keys for the phrase rather than read it off the screen
- Font is limited to Kanji, so we cannot display simplified Chinese characters
Given these limitations, this idea works best for Japanese Anki decks.